
Language Vision Models are Not Good at Science
Vision language models are unable to handle most “real-world chemistry and materials science tasks,” according to a new study.
A “vision–language model” is a type of AI that takes in both images and text, and then answers prompts that require combining the two. Such models can use an image to answer a written question, for example.
The current batch of language vision models — including Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, and Llama 3.2 90B Vision — should, in theory, be able to do this for scientific papers! It’d be great to, say, automatically interpret the data plotted in charts or look at a written protocol and then figure out which machines to use to run that experiment. This could save scientists a lot of time.
Unfortunately, data from a new benchmark, called MaCBench, suggests that vision-language models are not at all ready to do this type of work, at least for chemistry and materials science tasks. The paper was published in Nature Computational Science a few days ago.
The TL;DR is that MaCBench is a huge dataset with 1,153 tasks, including 779 multiple-choice questions and 374 numeric-answer questions.1 These tasks, together, cover three types of scientific work: data extraction (scraping numbers from charts or tables), experiment execution (identify equipment or figure out if an experiment is safe or not), and data interpretation (look at a chart and interpret the results). All of the questions in MaCBench were built from real scientific figures, including some generated by the authors to avoid giving the models anything they might have memorized from the web.
Those models that I mentioned earlier were evaluated using MaCBench. The results were not flattering. Of the four models evaluated, Claude 3.5 Sonnet did the best. But it, too, stumbled badly in many areas. Here’s a quick look at the results:
Data extraction: Average accuracy across models was 0.53 for extracting data from tables. Llama 3.2 90B Vision performed no better than random guessing. Models did well at identifying hand-drawn chemistry molecules (Claude 3.5 Sonnet: ~0.80 accuracy) but almost failed when asked about the isomeric relationship between chemical compounds (average ~0.24, baseline ~0.22).
Experiment execution: Models were able to identify equipment with an average accuracy of 0.77, but safety assessment questions dropped to 0.46.
Data interpretation: The benchmarks include some images obtained using atomic force microscopy, and the models interpreted them with a score of just 0.24. For mass spectrometry and NMR, which are widely used by biochemists to study proteins, the models averaged 0.35. These scores are really low.
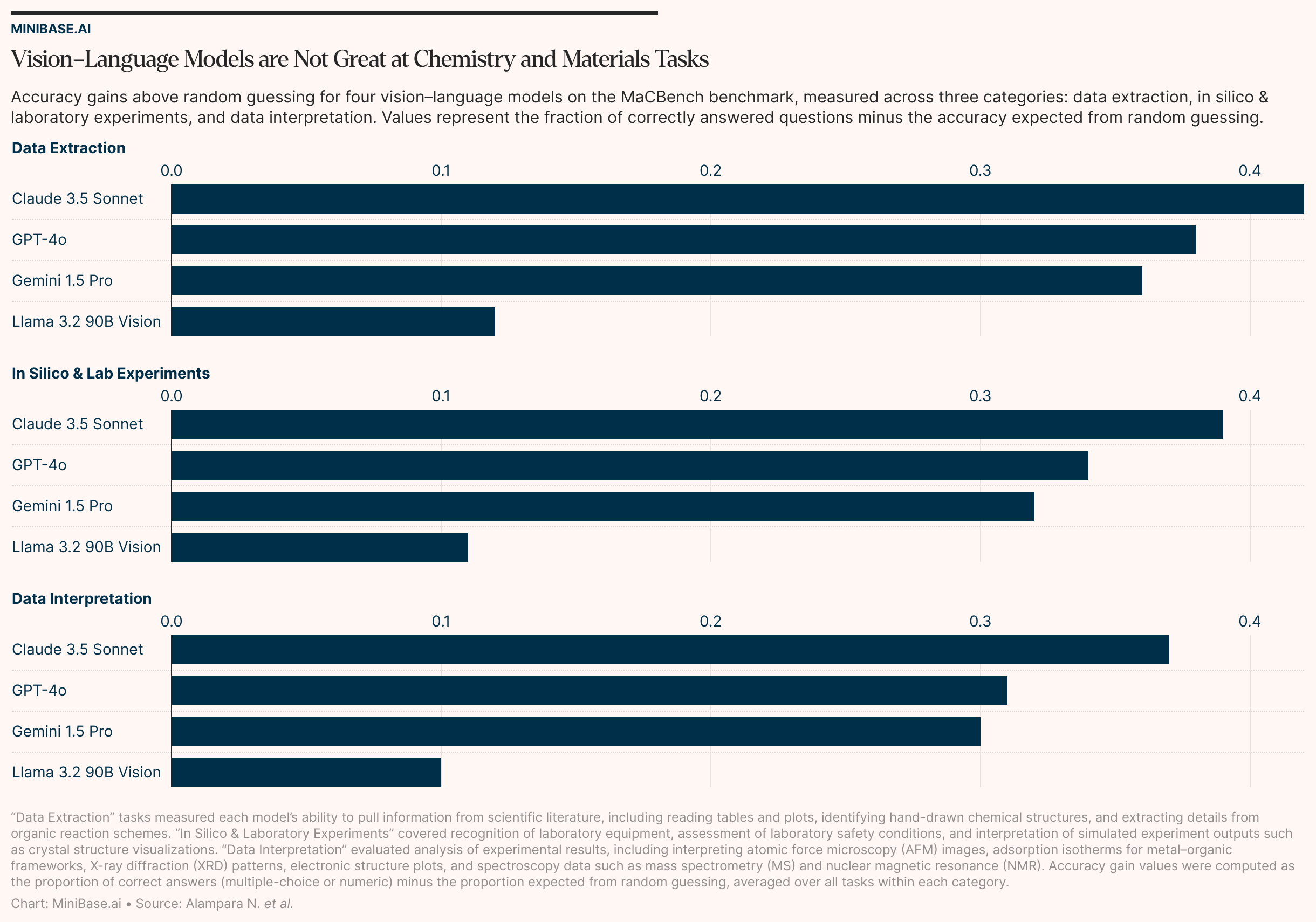
Note that performance in this context is actually “accuracy above random guessing.” In other words, the reported values are not the raw percentage of correct answers. Instead, the authors took each model’s raw percentage accuracy and subtracted its random, baseline accuracy. (There are four possible answers for each multiple-choice question, so a model would get 25% correct just by chance. If that model answered 85% of questions correctly, then its performance score would be given as 60%, or 0.60.)
To figure out why these models are so bad at certain tasks, the researchers did a series of ablation experiments. This basically means that they removed certain parts of the AI models to see which parts were causing the low scores. So they might give a model the exact same scientific information either as a text or as an image, for example, and then see how well it answers the same questions.
And it turns out that models perform way better when given the same data in text form rather than as an image. For one ablation experiment, the authors gave each model the exact same information (from an x-ray diffraction experiment, which is used to study a protein’s structure) as either typed-out numbers or as a graph. Models were about 35% more accurate at figuring out the x-ray data’s “peak positions” for the typed numbers. The authors also found, unsurprisingly, that a model’s performance correlates with how common the example is on the internet. Models were better at answering questions about more common protein structures, for example, suggesting they are using pattern matching rather than genuine reasoning.
These results do not bode well for the near-term creation of AI scientists. Dario Amodei, CEO of Anthropic, famously predicted in his essay, called Machines of Loving Grace, that “powerful AI could at least 10x the rate of [scientific] discoveries, giving us the next 50-100 years of biological progress in 5-10 years.” Unfortunately, that outcome seems more distant than many initially anticipated.
One way to resolve these issues is to move away from all-in-one or general purpose models. Instead, scientists could train smaller models — one fine-tuned for reading x-ray data, another for parsing certain data files, and so on — and string them together to build more accurate workflows. That would mean giving up the convenience of a single “ask it anything” system, of course, and it would require the data and know-how to fine-tune each model. But the payoff would be far higher accuracy and much more control over each scientific workflow.
The reason most scientists aren’t doing this now is because it takes so much work. Collecting enough labeled data for each sub-task is probably a months-long project in itself. Setting up the infrastructure to run multiple models in a row is another. But for now, if you want automation you can trust with real experiments, it’s probably the only realistic path.
We’re making it simple to train and deploy small AI models at minibase.ai. If you’re excited about this, join our Discord community!
– MiniBase Engineers
For example, “how many bones are in the human body” would be answered with 206.